from fastai2.vision.models.xresnet import *
from torchvision.models import resnet50
from fast_impl.core import *
arch_summary function plays major role while deciding parameter groups for discriminative learning rates. It gives a brief summary of architecture and is independant of input being passed. Thus we could use this function to understand architecture in a glance. We'll briefly explore various vision models from torchvision and pytorch-image-models to understand the use of arch_summary
Let's first quickly go through XResNet series offered by fastai2
def xresnet18 (pretrained=False, **kwargs): return _xresnet(pretrained, 1, [2, 2, 2, 2], **kwargs)
arch_summary(xresnet18)
Look at the Sequential layers from 4-7 all having two child layers, that's the meaning of [2,2,2,2] in the model definition. Let's go deeper and check what are these two children
arch_summary(xresnet18,verbose=True)
hmm... those are indeed ResBlocks, but what is ResBlock? Often it's good idea to print out model specific blocks, as sometimes, no. of input/output channels is the novelty of it (eg. WideResnet). We can use our get_module method for this which requires you to pass in list of indices to reach that block.
get_module(xresnet18,[4,0])
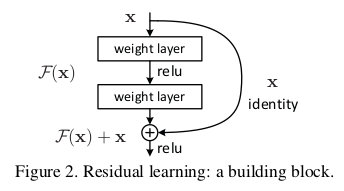
According to ResNet, we should have two weight layers, an identity (skip-connection) block and activation (ReLU), which is exactly ResBlock implements, with many tweaks introduced in the following years to improve the performance. A ConvLayer in fastai is Conv2D --> BatchNorm --> activation (ReLU). For the other variants of xresnet, we'll have exact same architecture but with more "groups" of ResBlock, such as
def xresnet34 (pretrained=False, **kwargs): return _xresnet(pretrained, 1, [3, 4, 6, 3], **kwargs)
def xresnet50 (pretrained=False, **kwargs): return _xresnet(pretrained, 4, [3, 4, 6, 3], **kwargs)
def xresnet101(pretrained=False, **kwargs): return _xresnet(pretrained, 4, [3, 4, 23, 3], **kwargs)
def xresnet152(pretrained=False, **kwargs): return _xresnet(pretrained, 4, [3, 8, 36, 3], **kwargs)
xresnet34 will have 4 groups having [3, 4, 6, 3] no. of ResBlocks and so on. We do get other variants of these base architecutures but as they're still experimental, I'll skip them for now. Now let's have a look at some architectures from torchvision.
from torchvision.models import MNASNet
mnasnet = MNASNet(1.0)
First 7 layers are stem of the network while 8 to 13 seems like some specific blocks of this architecture.
arch_summary(mnasnet,0)
arch_summary(mnasnet,[0,8])
Yup, they're InvertedResidual blocks. Let's find out what is InvertedResidualBlock
get_module(mnasnet,[0,8,0])
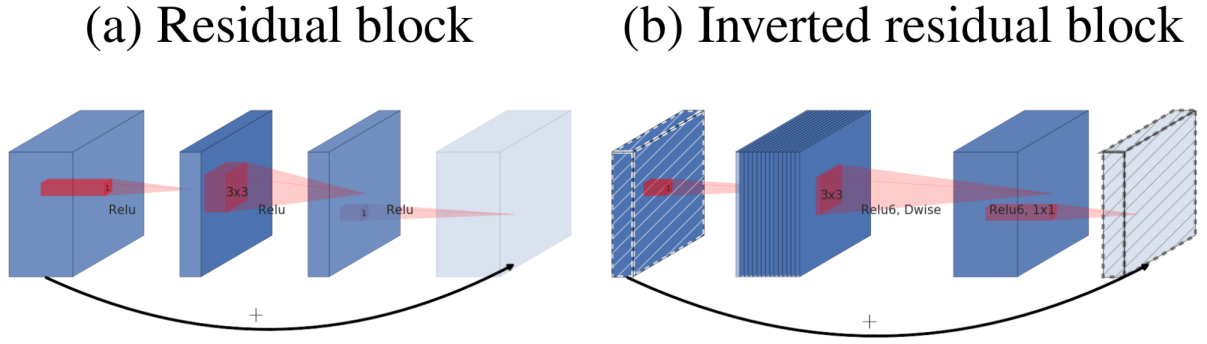
If you spot the difference, Residual Blocks have a fat input block being shrunk down before performing actual 3 × 3 convolution whereas inverted residuals have exact opposite picture.
A compact input block is first expanded, the convolution op is performed and again that block is compressed back to a compact version.
from torchvision.models import wide_resnet50_2
arch_summary(wide_resnet50_2)
If you look at the sequential layers, they do have no. of children exact similar to resnet50, while the key difference here is no. of input and output channels of their special block. Let's figure out what it is
arch_summary(wide_resnet50_2,[4])
You can also use the module names listed above to get required module, but you might need to take care of instantiating an object
arch_summary(wide_resnet50_2().layer1)
As discussed earlier, we'll be using get_module to find exact definition of Bottleneck block
get_module(wide_resnet50_2,[4,0])
Let's compare it with original resnet50. The idea proposed by WideResnet was having more channels in the bottleneck layers to exploit the parallelism offered by GPUs. Thus wideresnets take lesser time to train and to reach the error rate achieved by resnets.
get_module(resnet50,[4,0])